google使用ublacklist失效
google使用ublacklist失效 解决方案 首先怎么解决。将google浏览器的默认网址格式改为: 1https://www.google.com/search?q=%s 然后应该就可以继续正常使用。 问题描述 ublacklist插件能够屏蔽一些令人厌恶的网站,比如csdn。但是之前配置使用的ublacklist突然失效,无法屏蔽结果,找了很久都没办法解决这个问题,后面改用了一个google搜索引擎模板: 1https://www.google.com/search?q=%s ...

Freecontrol
FreeControl Unet的最初输入:编码之后的文本,加完噪音且之后的图像,两者进行交叉注意力层之后送入unet中 注:图像在加噪音之前还会经过一个VAE编码器 结构信息发现 论文中提到对图像的unet的中间状态进行PCA,其结果带有结构信息,所以提出了不需要为每个控制信息都额外的重新训练适配器,讲PCA得到的结构信息来控制生成图像的结构信息。 [!NOTE] 并不是将下面这些图像作为输入经过DDIM,得到中间层的unet然后做PCA,而是将这些当作结果图像,通过DDIM的可逆性,方向推得unet中间层然后做PCA得到的。 Analysis Stage 上面提到图像的结构可以使用PCA来得到,那么语义的结构应该怎么得到呢? Analysis Stage主要是为了计算BtB_tBt的,BtB_tBt 是某个语义结构子空间(structure subspace)的基,它用来提取结构表示: St=BtTFtS_{t}=B_{t}^TF_{t}St=BtTFt...

DDPM与DDIM
这篇文章主要记录DDPM和DDIM中的部分公式的推导,以及两者的简要对比。 Denoising Diffusion Implicit Models 主要分为加噪音和去噪音两个部分。 加噪音过程: x0(元素图像)−>x1−>x2....−>xt(加完噪音之后的图像)x_0(元素图像) -> x_1 -> x_2 .... ->x_t(加完噪音之后的图像) x0(元素图像)−>x1−>x2....−>xt(加完噪音之后的图像) 每一步的更新公式: 其中βt{\beta_t}βt 通常是一个随时间 t单调递增、数值很小的噪声调度(noise schedule) xt=1−βt xt−1+βt ϵt,ϵt∼N(0,I)x_t = \sqrt{1 - \beta_t}\, x_{t-1} + \sqrt{\beta_t}\, \epsilon_t, \quad \epsilon_t \sim \mathcal{N}(0,...

AttenGAN
AttnGAN:Fine-Grained Text to Image Generation 论文原址 简介 AttnGAN(Attentional Generative Adversarial Network) 是首个将**词级注意力机制(word-level attention)**系统性引入 GAN 文生图(Text-to-Image, T2I)任务 的工作。 其核心动机在于: 一次性直接生成高分辨率、高语义一致性的图像极其困难; 文本描述往往包含多个语义成分,不同词语应作用于图像的不同空间区域; 仅依赖全局句向量会导致细节缺失或语义漂移。 因此,AttnGAN 采用了两项关键设计: 多阶段逐步生成(Multi-stage Generation):从低分辨率到高分辨率逐步细化图像; 词级注意力机制(Fine-grained Attention):在生成过程中,让不同词动态关注不同的图像区域。 下图是论文中给出的直观示例: 不同颜色、形态相关的词,对应关注图像中不同的局部区域。 模型整体结构 AttnGAN...
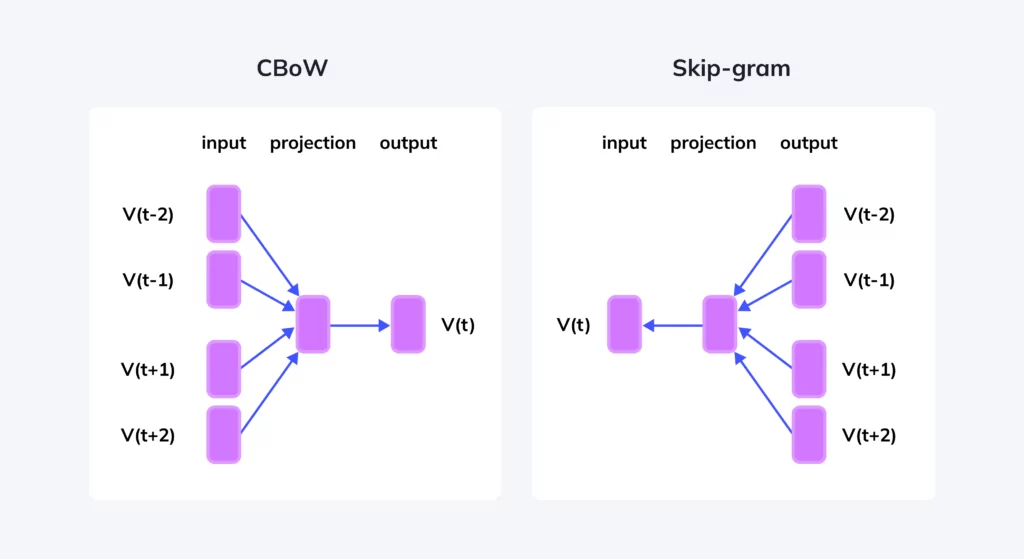
word2vec笔记
word2vec 笔记 word2vec 中的数据原理详解 首先明确这些模型的作用:通过自监督判别任务,训练有语义结构的词向量。 这里的的有语义结构的意思是相类似的词需要有较相近的词向量。 基于 Hierarchical softmax 的模型 CBOW 模型是根据上下文的单词来预测中心词的概率 Ship-gram 模型是根据中心词预测上下文词汇出现的概率 CBOW 模型 对于模型的讲解原文章以及写的很好了,这里仅仅做问题补充。 1.首先回答原文章留出的思考题: 答案是也满足归一化操作,为什么呢? 因为对每一个节点都是进行的 sigmod 操作,那么对于每一个非叶节点,左子节点的概率和右子节点的概率和一定是为 1 的。这样的话可以看作将一块饼分成很多块,每一次都是在上一次分完的基础上进行再分,所以无论怎么分割,最终饼的总和是不变的,始终为 1 上面是一个具体的例子。对于一个上下文 w,所有可能的中心词的概率之和一定为 1,即所有叶子节点的输出结果之和一定为 1. 2.CBOW...

SAR图像像素点转化为经纬度
SAR 图像像素点转化经纬度 有的 tiff 格式的 SAR 图像其可能存在 CRS 和转化矩阵,可以使用这两个参数将 SAR 图像中的像素点转化为实际的经纬度。 CRS 地理坐标是用来表示地球上的具体某一点的坐标系,类似于二维平面下有极坐标系和直角坐标系一样,CRS 也有很多种不同的坐标系,下面输出的 CRS 就是数据集使用的地理坐标系,但是这个不是标准的经纬度坐标,输出 CRS 信息是用来描述这个坐标系的具体参数,但是实际使用的时候并不需要全部了解这些参数的意义,直接整体使用即可。 将像素点转化为经纬度有两步仿射变化: 使用 transform 矩阵将像素点转化为该数据集下的 CRS 地理坐标系。 将该数据集的坐标系转化为标准经纬度坐标系。 第一步的 transform 矩阵是 tiff 图像种可以直接获取的,如下面所示。但是如果输出的是单位矩阵的话表示该数据集没有可使用的转化矩阵,没办法转化为 CRS 坐标。 1234567891011import rasterio# 打开 TIFF 文件with...

Gaming Behavior Predict
Gaming Behavior Predict 小组作业 背景 游戏或许是一种策略游戏,但数据集显示,玩家行为背后的指标远非如此简单。在本篇笔记中,我们将深入分析一个捕捉在线游戏行为细微差别的数据集,挖掘隐藏的模式,并构建一个预测模型,以检验我们能否预测玩家的参与度。 参考此部分代码 商业问题 如何根据之前玩家的行为预测玩家在游戏中的参与度。通过预测玩家的活跃程度,游戏开发商可以提前识别出潜在的流失玩家,从而采取针对性的措施,如推送奖励、个性化推荐等,提高玩家的留存率和忠诚度。 玩家重要特征选取:并不是所有特征对玩家的参与度都有很重要的作用,玩家的参与度往往是由几个重要的特征决定的,找到重要的特征有利于商家针对性的优化产品。 数据 使用公开数据集 Predict Online Gaming Behavior...
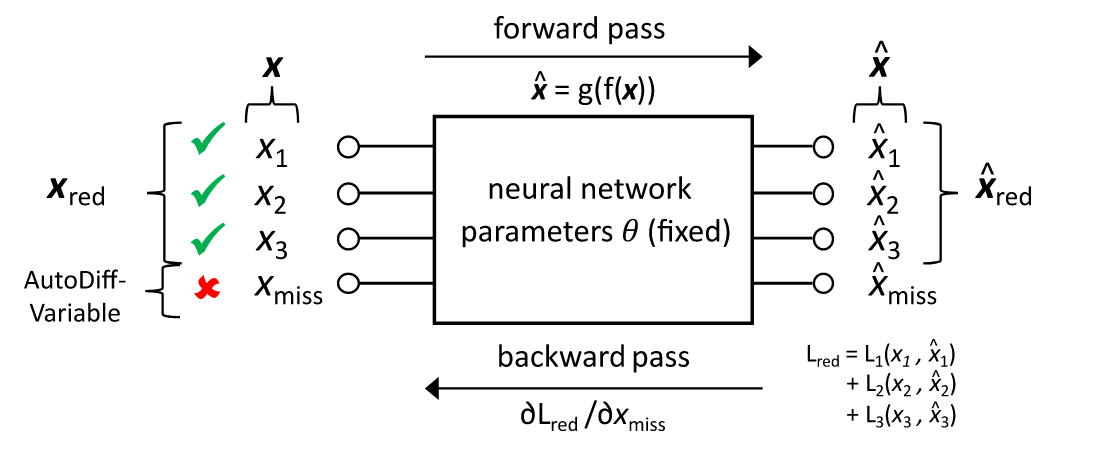
基于自编码器补全缺失特征值
Using Autoencoders and Automatic Differentiation to Reconstruct Missing Variables in a Set of Time...
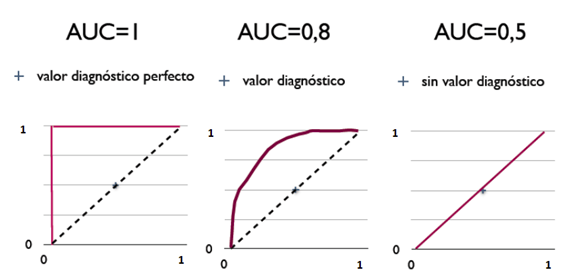
ROC曲线和AUC值
ROC曲线和AUC值 ROC曲线 ROC曲线(Receiver Operating Characteristic)全称:受试者工作特征曲线 提到ROC曲线就要先说明一下两个概念:FPR(伪正类率),TPR(真正类率) 它们都是对分类任务的一个评测指标。 对于一个二分类任务(假定为1表示正类, 0表示负类),对于一个样本,分类的结果总共有四种: 类别实际为1,被分为0,FN(False Negative) 类别实际为1,被分为1,TP(True Positive) 类别实际为0,被分为1,FP(False Positive) 类别实际为0,被分为0,TN(True Negative) 而FPR(False Positive Rate)= FP /(FP + TN),即负类数据被分为正类的比例 TPR(True Positive Rate)= TP /(TP + FN),即正类数据被分为正类的比例 简而言之: FPR:对->对 TPR:错->对...

Image-to-Image Translation with Conditional Adversarial Networks 论文
Image-to-Image Translation with Conditional Adversarial Networks 论文 论文原址 1.实现的功能 实现了将图片转成另外一个图片,具体使用包括:根据手稿生成画作,冬天图像转化为春天等等。 2.网络模型 使用有监督的GAN,通过G生成器将x转化为G(x),然后通过D辨别器区分真实的图像和生成的图像。 通俗理解GAN 2.1 网络中的特殊点 2.1.1 同时生成高频和低频信息 低频图像主要包含整体形状,轮廓等。高频图像主要包含边缘等细节信息。 模型的损失函数为: 其中的λLL1(G)\lambda L_{L1}(G)λLL1(G)是指通过G生成的图像和真实图像之间的差距 这个是对整个图像进行求损失期望,理所应当的这个误差描述的是整体之间的差异,通过这个能够很 好的对低频信息进行建模。 对高频信息的建模是通过PatchGAN实现的,正常的GAN其中的辨别器的输入是两个...