Freecontrol
FreeControl
Unet的最初输入:编码之后的文本,加完噪音且之后的图像,两者进行交叉注意力层之后送入unet中
注:图像在加噪音之前还会经过一个VAE编码器
结构信息发现
论文中提到对图像的unet的中间状态进行PCA,其结果带有结构信息,所以提出了不需要为每个控制信息都额外的重新训练适配器,讲PCA得到的结构信息来控制生成图像的结构信息。
[!NOTE]
并不是将下面这些图像作为输入经过DDIM,得到中间层的unet然后做PCA,而是将这些当作结果图像,通过DDIM的可逆性,方向推得unet中间层然后做PCA得到的。

Analysis Stage
上面提到图像的结构可以使用PCA来得到,那么语义的结构应该怎么得到呢?
Analysis Stage主要是为了计算的, 是某个语义结构子空间(structure subspace)的基,它用来提取结构表示: 其中Ft是unet的特征,St是结构图
下图计算出来的相当于是以man这个词语为核心的语义结构字体空间的基
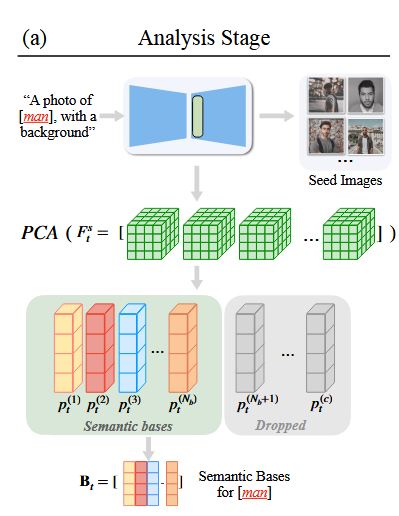
具体流程为:
1.根据输入的特定的文本信息,通过文生图模型生成一组seed image
2.然后将生成这些图像的unet的中间状态进行PCA计算, 因为seed image 有一组图像,所以这一组图像在同一个unet层会生成一组特征向量,需要将这些特征向量拼接起来,然后再使用PCA计算
3.然后根据PCA的结果选取部分特征向量作为结构指导。
Synthesis Stage
上面的内容简要介绍了怎么从文本和控制图像中提取控制结构,那么怎么将两者进行对齐呢,Synthesis Stage的核心是将原始生成的图像的结构和控制图像的结构图进行组合,使得前者的结构不断毕竟后者的结构以实现控制结构。
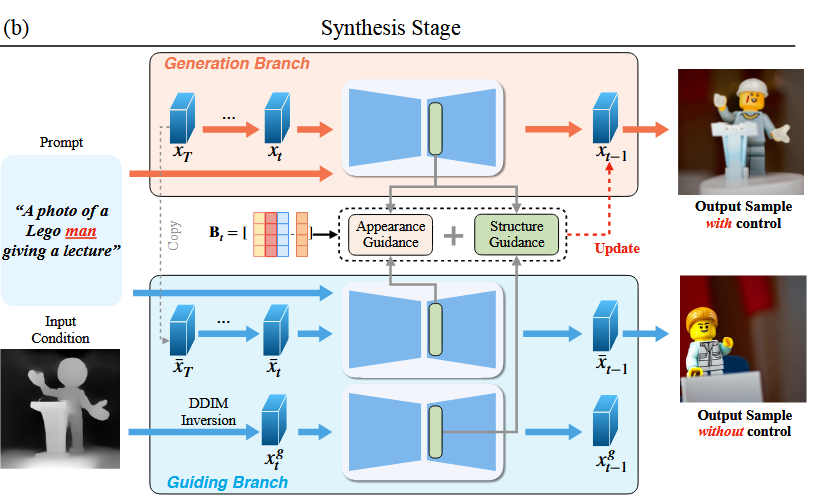
Synthesis Stage又分为Guiding Branch和Generation Branch两部分
Guiding Branch
Guiding Branch对应上图的蓝色部分
其中,Input Condition 是输入的控制图像,是预期结果生成图像的结构。
现在想要获得这个图像在unet中某时间步和某层的结构图,可以将这个图像看作最终的输出,然后根据一个结果图像反向获得其在unet的结构图
正常的正向扩散模型流程是:
输入噪点图 -> VAE encoder -> 和文本结合送入unet -> VAE decoder -> result
第一步是反向经过VAE decoder,这个的逆过程相当于经过VAE encoder,然后再是通过DDIM inversion得到在unet中具体层具体时间步的特征向量。
DDIM inversion
本博客中另一篇文章DDIM于DDPM中介绍了DDIM的正向流程,其中想要获得下一步的去噪效果需要先估算干净的图像,然后再加噪音回下一个时间步。此处的结果可以相当于干净的图像,可以通过固定的加噪音到指定的时间步,公式如下所示:
有了某一步的特征之后就能获得对应的结构指导图(Structure Guidance)
Generation Branch
再看上面的分支,通过输入噪音图像和文本信息,可以直接正向的结构指导图
MASK
初始输入的噪音图像和文本送入unet中会经过cross attention层,通过这一层可以得到一个注意力图,表示当前文本对图像中注意力主要关注的地方(经过归一化处理的),这个注意力图称为mask,其中约接近1,表示越重要,越需要结构控制,接近则表示不需要结构控制。
注:可以将mask设置为全1,此时表示所有点都需要结构控制。
结构融合
有了指导的结构图和当前实际的结构图之后,就需要进行使用结构指导。

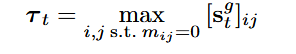
如上图公式所示,分为两个部分,第一个部分是前景指导,第二个是背景指导。
其中 是Mask中的一个点的权重,
表示t时间步Generation Branch生成的结构图
表示Guiding Branch生成的结构图
此处使用MSE来表示这两者的差距并且使用注意力来控制对结构的敏感度,
后面的部分用来惩罚不要过多控制背景。
所以上面这个公式主要是一个惩罚项,但结构与想要的不一致的时候会变大
内容风格控制
添加了结构控制之后可能会影响生成的风格,所以分别计算不用结构控制生成的图像和用结构控制生成的图像的外观向量:
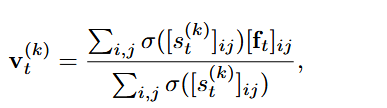
然后得到来控制风格和之前相似,其中带上划线的V是不带控制结构生成的图像
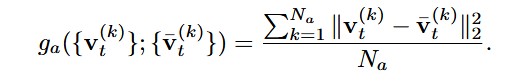
最终的更新公式为:
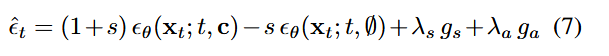
其中第二项是不添加文本信息的生成噪音
在CFG中是如此定义的:
其意义是加上只由语义产生的噪音部分,让文本的条件被放大,然后将这个式子化简之后就能得到(7)的前两项
补充
VAE编码器
VAE编码器是将一张真实图像压缩到一个连续、可加噪、可扩散的 latent 表示。
一般来说图像直接经过duffion网络,会造成参数量极大,训练时间过大
例子,输入图像是3 _ 512 _ 512的,经过VAE编码器之后变成4 _ 64 _ 64,空间维度降低了,但是物体结构和语义分布仍在,最终经过duffion之后,再通过VAE解码器恢复到原始图像的尺寸
VAE生成的并不是一个固定的图像,而是为每一个通道生成一个标准差和方差,然后进行采样
VAE的训练
VAE是单独进行训练的,不会直接和扩散模型进行训练。和自编码器一样,VAE的输入和输出都是一幅同样的图像。
loss函数
其中 :原始图像(像素空间)
:重建后的输出
:重建损失(Reconstruction Loss)
:潜在变量(Latent Variable)
: 编码器给出的后验分布
:潜在空间的先验分布
:KL 散度正则项
:KL 权重系数(正则强度)
正则项的加入是为了将潜在空间的分布拉向标准正态分布,这样解码器就能从一个近似标准正态分布分布的数据中恢复原始的图像。