这篇文章主要记录DDPM和DDIM中的部分公式的推导,以及两者的简要对比。
Denoising Diffusion Implicit Models
主要分为加噪音和去噪音两个部分。
加噪音过程:
x0(元素图像)−>x1−>x2....−>xt(加完噪音之后的图像)
每一步的更新公式: 其中βt 通常是一个随时间 t单调递增、数值很小的噪声调度(noise schedule)
xt=1−βtxt−1+βtϵt,ϵt∼N(0,I)
多步加噪音可以合成一步:
xt=αˉtx0+1−αˉtϵ,ϵ∼N(0,I)
其中
αt=1−βt
αˉt=i=1∏tαi
也有的地方记作:
zt=αtz0+σtϵt
其中αt表示信号保留多少,σt表示噪音注入多少,并且通常满足:(这样是为了保持方差不会变大,假如输入的z0的方差为1)
αt2+σt2=1
具体公式推导暂时不补充
去噪音过程
去噪音流程
1.还原干净样本估计 z^0
由加噪音的公式:
zt=αtz0+σtϵ,ϵ∼N(0,I)
解得z^0:这个是由当前时间步Zt 估计完全去完噪音之后的结果,其中ϵ^t是去噪音网络的结果.
z^0=αtzt−σtϵ^t
2.生成下一步 Zt−1,使用估计的完全去完噪音的z^0,重新使用加噪音的过程来预计去噪音的下一步结果,其中使用的去噪音网络和上一步是同一个
zt−1=αt−1z^0+σt−1ϵ^t
为什么不直接使用xt=1−βtxt−1+βtϵt,ϵt∼N(0,I) 推得
x_t−1=(xt−βt ϵt)/1−βt
这样直接推得下一步的去噪音效果呢?
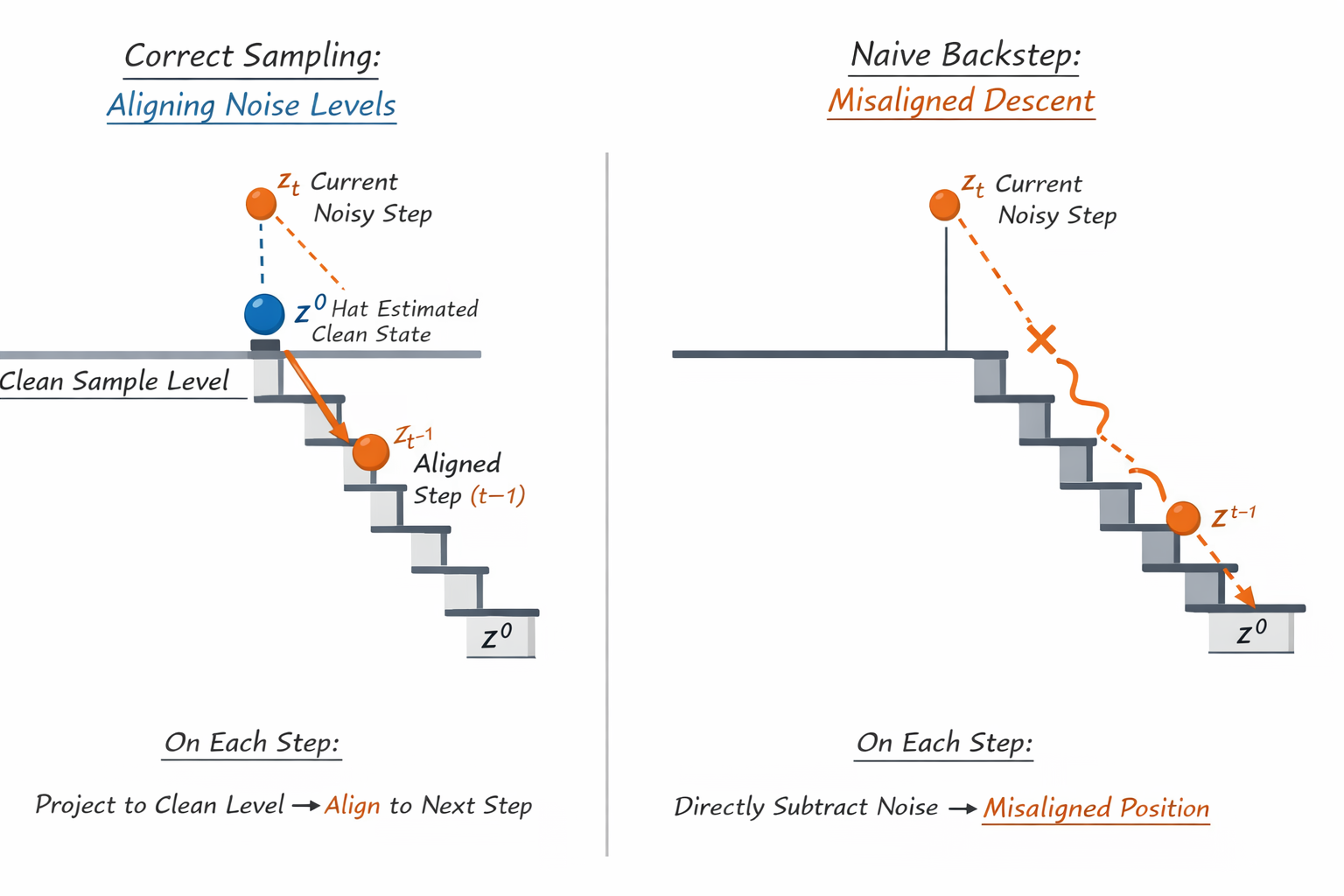
每一个时间步的Zt都对应的一个分布,比如“清晰度 20% + 噪声 80%”,去噪音的过程就相当于要将每一步的降噪结果放到对应的分布中去,即要将下图中的小球放到指定的台阶中去。
如果使用直接前去噪声的方式,如右侧所示:每次直接减去噪音,可能会导致一次跳很多个台阶,并且这个错误会累积,经过多轮迭代,错误将会越来越大。
如果使用原始的方式,如左侧所示:先计算 z^0, 相当于将图像放到最底层,然后再往指定台阶上面放,这样就能较好的确保每一步的降噪结果符合分布。
从另一种角度解释:加噪音的时候是一次性加上的,实际并不知道每一步具体加的噪音值是多少
那么去噪音网络生成的结果具体的含义是什么呢?
降噪是去噪音的逆过程,那么是不是去噪音网络生成的是每一个时间步需要减去的噪音呢?
有了上面的分析,可以知道肯定不是这样的。去噪网络生成的是对下面公式中ϵ的模拟值
zt=αˉtz0+1−αˉtϵ,ϵ∼N(0,I)
但是上面的ϵ是一个随机取出来的值,并且每一步都不一样,这怎么具体拟合呢?
虽然ϵ是随机取值的,但是具体的取值已经在加噪音过程中被记录在Zt 中了,网络模型应该能够通过分析 Zt 和时间步 t 来分析出加噪音中使用的具体ϵ是
去噪音网络
通过加噪音部分得到了zt,然后开始一步一步预测噪音,使用神经网络进行预测:
ϵ^t=ϵθ(zt,t)
其中t是时间步,输出会对每个像素点的每个通道都预测一个μ,σ ,然后使用最终的预测的噪音为
ϵ^t=μθ(zt,t)+σθ(zt,t)η
η∼N(0,I)
这一步叫做重采样,如果直接从N(μ,σ)中进行采样的话,无法进行梯度的传递。
具体的网络最常使用的是U-NET(stable duffion)
损失函数
L=Ex0,t,ϵ[∥ϵ−ϵθ(xt,t)∥2]
其中的ϵ 是zt=αtz0+σtϵ,ϵ∼N(0,I) 中的噪音,而不是具体每一步中添加的噪音。对于不同的时间步有不同的ϵ 。
Denoising Diffusion Probabilistic Models
加噪音过程
加噪音过程和上面的DDIM一致。
去噪音过程
由前面的加噪音过程可以知道:
q(xt∣xt−1)=N(αtxt−1, βtI),αt=1−βt
q(xt−1∣x0)=N(αˉt−1x0, (1−αˉt−1)I),αˉt=i=1∏tαi
这两个等式分别从x0 xt的角度去描述xt−1的分布情况,那么怎么计算在x0,xt同时发生的时候计算Xt−1的分布情况呢。
可以使用贝叶斯全等式:
q(xt−1∣xt,x0)=q(xt∣x0)q(xt∣xt−1,x0)q(xt−1∣x0)
由于马尔可夫性(给定 xt−1后,xt 与 x0 独立):
q(xt∣xt−1,x0)=q(xt∣xt−1)
所以:
q(xt−1∣xt,x0)=q(xt∣x0)q(xt∣xt−1)q(xt−1∣x0)
上面式子的右边都能够得到,并且都是高斯分布,所以可知左边仍然是一个高斯分布,通过计算(此处省略具体计算步骤)可以知道左边的协方差为
β~t=1−αˉt1−αˉt−1βt
均值为:
μ~θ(xt,x0)=1−αˉtαˉt−1βtx0+1−αˉtαt(1−αˉt−1)xt
现在我们知道了xt−1的分布,直接从这个分布中进行采样就可以,整体的流程为:
1.和DDIP一样,需要先计算当前时间步对干净图像的估计:
x^0=αˉtxt−1−αˉtϵ^t
2.根据xt−1的分布采样数据,此处同样使用重采样
xt−1=μθ(xt,t)+β~tη,η∼N(0,I)
补充一张DDPM论文中的算法流程:

DDIM VS DDPM
| 维度 |
DDPM |
DDIM |
| 全称 |
Denoising Diffusion Probabilistic Models |
Denoising Diffusion Implicit Models |
| 核心思想 |
学习并采样反向概率分布 |
沿一条隐式确定性轨迹生成 |
| 正向加噪(forward) |
与 DDIM 相同:高斯马尔可夫链 |
与 DDPM 相同(常用设定) |
| 前向单步 |
(xt=1−βtxt−1+βtϵt) |
同 DDPM |
| 前向闭式 |
(xt=αˉtx0+1−αˉtϵ) |
同 DDPM |
| 网络输出 |
(ϵ^t=ϵθ(xt,t))(最常见) |
同一个网络,输出相同 |
| 是否多一个网络 |
没有 |
没有 |
| 是否显式建模概率分布 |
是(反向是高斯) |
否(隐式映射) |
| 反向一步形式 |
采样 (pθ(xt−1∣xt)) |
确定性计算 (xt−1) |
| 反向更新公式(核心) |
(xt−1=μθ+β~tη) |
(xt−1=αˉt−1x^0+1−αˉt−1ϵ^t) |
| 损失函数 |
L=Ex0,ϵ,t[∥ϵ−ϵθ(xt,t)∥2] |
与 DDPM 一致 |
| $(\tilde\beta_t) $的作用 |
真实后验方差,来自高斯融合 |
不需要(确定性版本) |
| 去噪稳定性 |
高(概率一致) |
高(轨迹一致) |
| 是否可跳步 |
不自然(需额外求解器) |
天然支持 |
| 常用采样步数 |
500–1000 |
10–100 |
| 采样速度 |
慢 |
快 |
| 可复现性 |
较弱(有随机采样) |
强(同初始噪声必同结果) |
| 多样性 |
高 |
较低(可通过 (\eta>0) 增强) |
| 理论视角 |
近似真实后验的随机采样 |
同一边缘分布下的隐式轨迹 |
| 典型用途 |
理论严谨、早期基线 |
实际生成、加速采样 |
LDDPM=Ex0,t,ϵ[∥ϵ−ϵθ(xt,t)∥2]
βt 的选择设定
线性(Linear)βt(DDPM 原始版本)
βt=βstart+T−1t−1(βend−βstart)
常用取值(经验值)
βstart=10−4,βend=0.02,T=1000
图像如下:
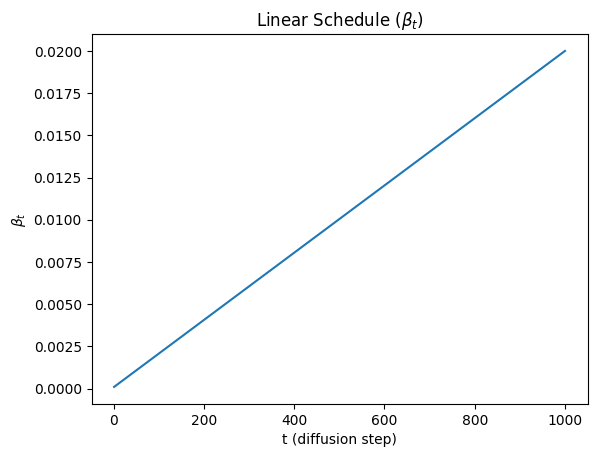
特点是:简单,稳定,但是早期时间步增长过快
Cosine Schedule βt
来自论文Improved Denoising Diffusion Probabilistic Models中
αˉt=cos2(1+ss⋅2π)cos2(1+st/T+s⋅2π),s=0.008
不是直接定义βt,而是先定义累计量
然后再推出
βt=1−αˉt−1αˉt
优点:前期噪音增长跟俺,后期平滑,生成质量更好
取T=1000,s=0.008,βt关于t的图像如下:
二次(Quadratic)
βt∝(Tt)2
指数(Exponential)
βt=β0⋅λt
Sigmoid(平滑过渡)
βt=βmin+(βmax−βmin)⋅sigmoid(k(t−T/2))