AttenGAN
AttnGAN:Fine-Grained Text to Image Generation
简介
AttnGAN(Attentional Generative Adversarial Network) 是首个将**词级注意力机制(word-level attention)**系统性引入 GAN 文生图(Text-to-Image, T2I)任务 的工作。
其核心动机在于:
- 一次性直接生成高分辨率、高语义一致性的图像极其困难;
- 文本描述往往包含多个语义成分,不同词语应作用于图像的不同空间区域;
- 仅依赖全局句向量会导致细节缺失或语义漂移。
因此,AttnGAN 采用了两项关键设计:
- 多阶段逐步生成(Multi-stage Generation):从低分辨率到高分辨率逐步细化图像;
- 词级注意力机制(Fine-grained Attention):在生成过程中,让不同词动态关注不同的图像区域。
下图是论文中给出的直观示例:
不同颜色、形态相关的词,对应关注图像中不同的局部区域。

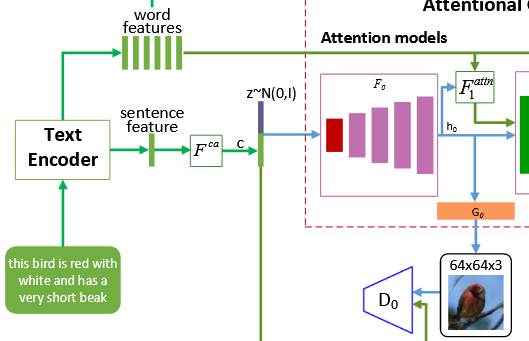
模型整体结构
AttnGAN 的整体结构如下图所示:
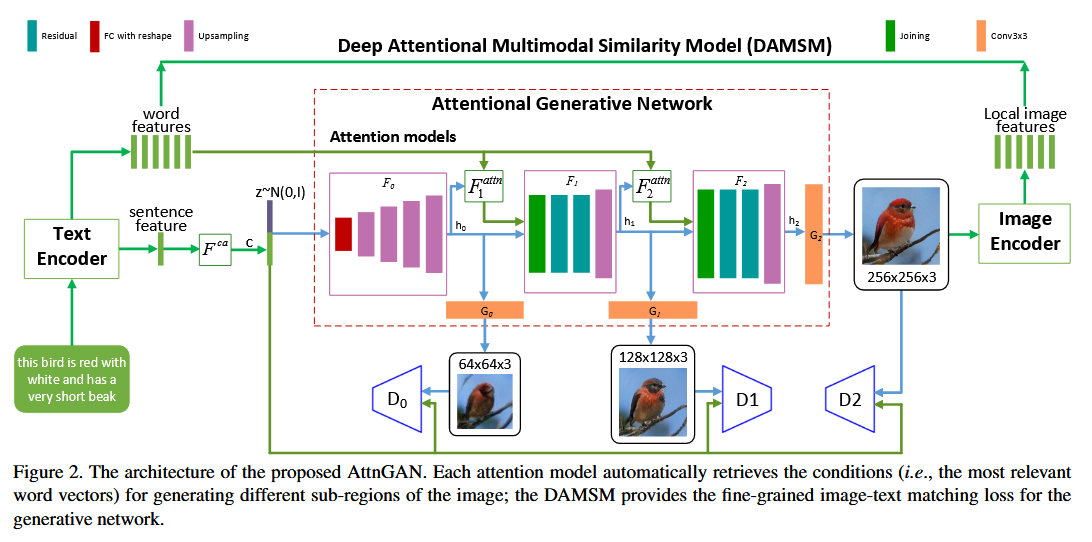
整体可以分为三大模块:
- 文本编码器(Text Encoder):将文本描述编码为词向量与句向量;
- 多阶段生成器 + 判别器(Stacked GAN):逐步生成高分辨率图像;
- 注意力机制与 DAMSM 约束:在生成过程中引入细粒度语义对齐约束。
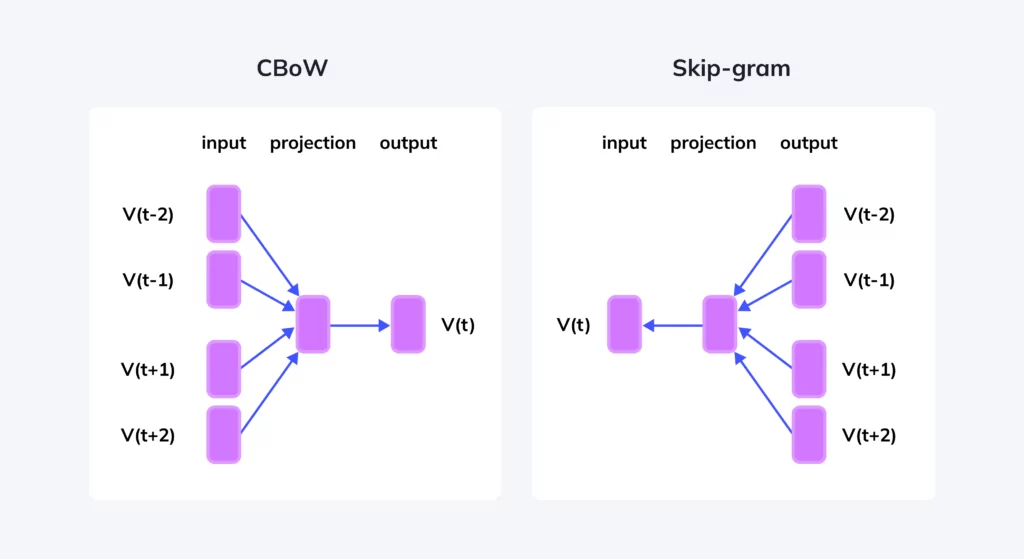
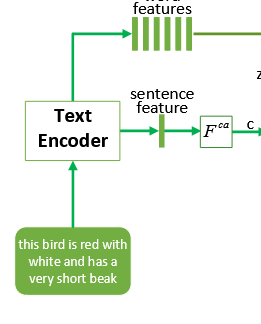
文本编码(Text Encoding)
词嵌入(Word Embedding)
- 初始化一个可学习的词嵌入表(Embedding Matrix);
- 每个输入单词被映射为一个低维连续向量;
- 该阶段不包含上下文信息,仅是静态词表示。
设句子长度为 (T),嵌入维度为 (d_w):
BiLSTM 获取上下文词特征
由于词语含义依赖上下文,AttnGAN 使用 双向 LSTM(BiLSTM) 对词嵌入进行编码:
- 前向 LSTM 捕获左侧上下文;
- 后向 LSTM 捕获右侧上下文;
- 拼接前向与后向隐藏状态,作为最终词特征。
得到:
- 词特征矩阵:
- 句向量(Sentence Feature):
- 由 BiLSTM 最后一个前向状态和第一个后向状态拼接得到
- 由 BiLSTM 最后一个前向状态和第一个后向状态拼接得到
条件增强(Conditioning Augmentation, CA)
为什么需要条件增强?
如果直接使用确定性的句向量作为生成条件,会导致:
- 文本到图像映射过于僵硬;
- 对同一文本只能生成有限多样性的图像;
- 训练不稳定,容易过拟合。
因此,AttnGAN 引入 条件增强(CA),将文本条件建模为一个条件分布。
CA 的具体形式
不会直接生成数据,而是生成 然后根据这个正态分布进行取值。这样做的好处是随机性更强,对于同样的句向量,每次输出的结果会不一样。
给定句向量 ,通过一个全连接网络 输出:
随后从高斯分布中采样:
上面使用重参数化技巧,不直接从中进行采样的原因是这样无法传递的梯度,因为是随机从分布中进行采样的,所以通过在中采样采样然后再进行缩放。
这一步使得:
同一文本在语义一致的前提下,具有随机性与多样性。
与噪声的融合方式
CA 输出的条件向量 并不会与噪声相加,而是:
其中:
- 随机噪声;
- 拼接(concatenation)后作为 Stage-I 生成器的输入。
多阶段 GAN 生成(Stacked GAN)
AttnGAN 采用 多阶段生成结构,每一阶段对应一个分辨率。
生成器(Generator)
- 每个阶段的生成器输出不同尺寸的图像;
- Stage-I:生成粗略的低分辨率图像(结构与颜色);
- 后续 Stage:在前一阶段特征基础上,逐步引入细节;
- 从 Stage-II 开始,引入 词级注意力机制。
判别器(Discriminator)
每一阶段对应一个判别器 (D_i),其输入为:
判别器在训练时会测试 三类样本:
- 真实图像 + 匹配文本(Real–Matched)
- 真实图像 + 不匹配文本(Real–Mismatched)
- 生成图像 + 匹配文本(Fake–Matched)
判别器并不会直接比较“真实图像 vs 生成图像”,
而是通过学习判别函数,隐式建模真实分布与生成分布的差异。
词级注意力机制(Fine-Grained Attention)
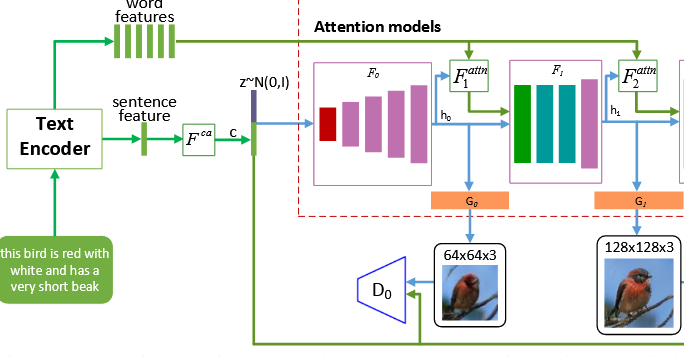
设计动机
不同词语应关注图像的不同区域,例如:
- “red” → 颜色区域
- “beak” → 鸟喙区域
因此,需要在生成过程中动态建立 词 ↔ 图像区域 的对应关系。
空间映射(Word-to-Image Projection)
词特征维度与图像特征维度不同,需进行空间映射:
其中:
- (U):可学习的线性映射矩阵;
- (\mathbf{e}'):与图像特征通道数一致的词特征。
注意力权重计算
本文的注意力计算使用点乘,既直接使用每个词向量和每个点进行相乘计算这个词相对这个点的注意力,然后在词维度上做softmax,这意味着每个像素对所有词的注意力之和为1.
对每一个图像空间位置 (i),与所有词 (j) 计算相似度:
随后对 词维度做 softmax:
得到该位置的上下文向量:
该上下文向量再与图像特征融合,用于生成。
[!NOTE]
此处是将特征进行拼接,故两个融合之后的特征维度是有所扩充的,最后再通过生成器将维度将到3维(RGB)
DAMSM 损失(Deep Attentional Multimodal Similarity Model)

DAMSM 的作用
DAMSM(Deep Attentional Multimodal Similarity Model)是一个独立的跨模态对齐模型,其核心目标不是判别真假,而是学习图像与文本之间的语义相似度度量。
DAMSM 的主要作用包括:
- 约束生成图像与文本在词级(word-level)和句级(sentence-level)语义空间中保持一致;
- 提供细粒度的监督信号,弥补 GAN 判别器仅能给出整体、弱语义反馈的不足。
之所以称 DAMSM 提供的是“细粒度”监督,是因为其相似度计算并不局限于“整幅图像 ↔ 整句话”,而是进一步建模了:
- 单词 ↔ 图像局部区域之间的对应关系;
- 整句话 ↔ 整幅图像之间的全局语义一致性。
在训练过程中,DAMSM 会计算每一个词与图像中所有空间位置特征的相似度,并通过注意力机制聚合,从而判断该词是否能够在图像的某些局部区域中被“找到”。如果某些词语(如颜色、部件或属性)未能在生成图像中得到正确体现,DAMSM 会对这些词对应的区域产生明确的负反馈梯度。
相比之下,GAN 判别器只能判断图像与文本在整体层面是否匹配,无法指出具体是“哪个词”或“哪个区域”出现了问题。DAMSM 正是通过这种词–区域级别的跨模态对齐约束,为生成器提供了更具语义指向性的训练信号,从而显著提升生成图像在细节层面与文本描述的一致性。7.2 与判别器的区别
| 维度 | GAN 判别器 | DAMSM |
|---|---|---|
| 监督位置 | 整幅图像 | 图像局部区域 |
| 监督对象 | 整句话 | 单词 + 句子 |
| 输出信号 | 单一标量 | 多词、多区域相似度 |
| 是否可定位 | 否 | 是 |
| 语义解释性 | 弱 | 强 |
两者功能互补,并不重复。
整体损失函数
最终训练目标由以下几部分组成:
- 多阶段对抗损失(GAN Loss)
- 条件一致性损失(Mismatch Penalty)
- DAMSM 跨模态相似度损失
总结
AttnGAN 的核心贡献在于:
- 将词级注意力引入 GAN 文生图;
- 使用多阶段生成逐步提升图像质量;
- 通过 DAMSM 提供稳定、细粒度的跨模态监督。
该工作为后续高质量 T2I 模型(如 DM-GAN、DF-GAN 等)奠定了基础。