word2vec笔记
word2vec 笔记
首先明确这些模型的作用:通过自监督判别任务,训练有语义结构的词向量。
这里的的有语义结构的意思是相类似的词需要有较相近的词向量。
基于 Hierarchical softmax 的模型
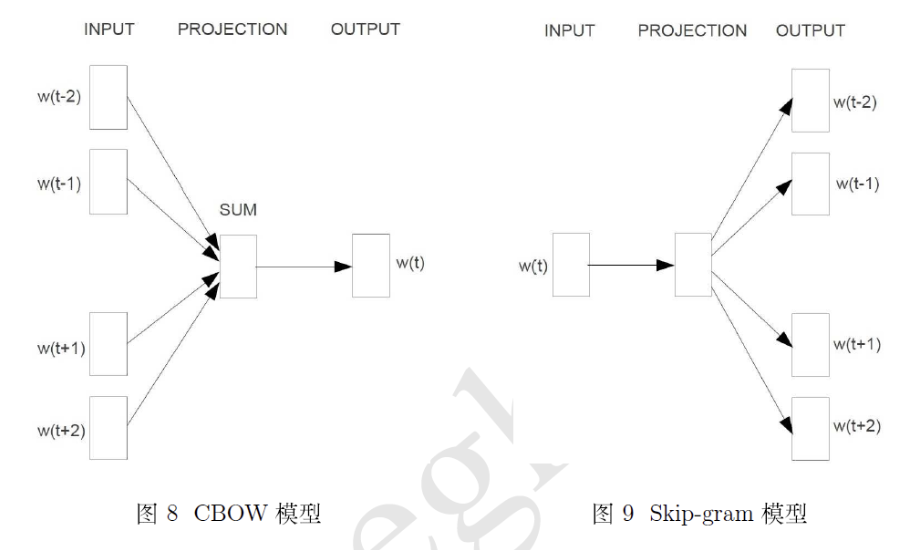
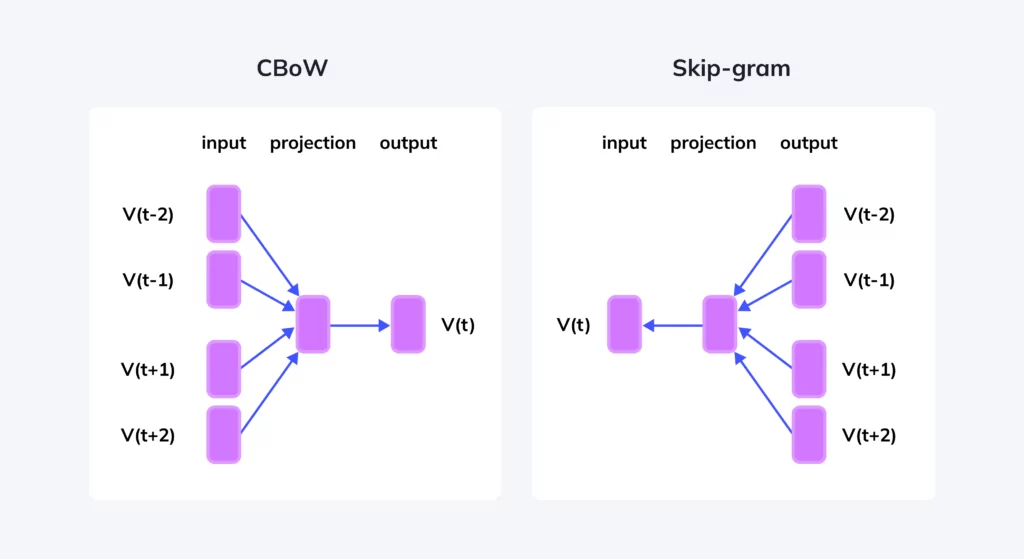
CBOW 模型是根据上下文的单词来预测中心词的概率
Ship-gram 模型是根据中心词预测上下文词汇出现的概率
CBOW 模型
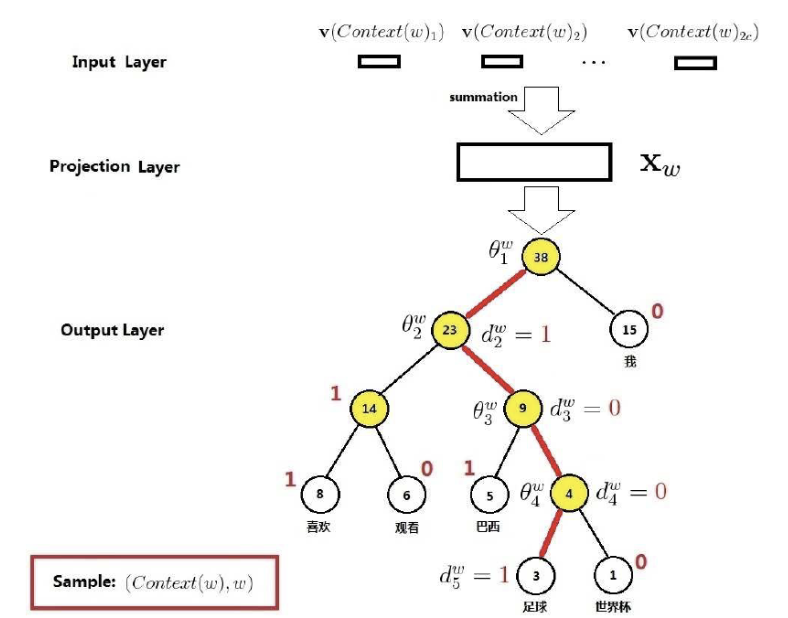
对于模型的讲解原文章以及写的很好了,这里仅仅做问题补充。
1.首先回答原文章留出的思考题:

答案是也满足归一化操作,为什么呢?
因为对每一个节点都是进行的 sigmod 操作,那么对于每一个非叶节点,左子节点的概率和右子节点的概率和一定是为 1 的。这样的话可以看作将一块饼分成很多块,每一次都是在上一次分完的基础上进行再分,所以无论怎么分割,最终饼的总和是不变的,始终为 1
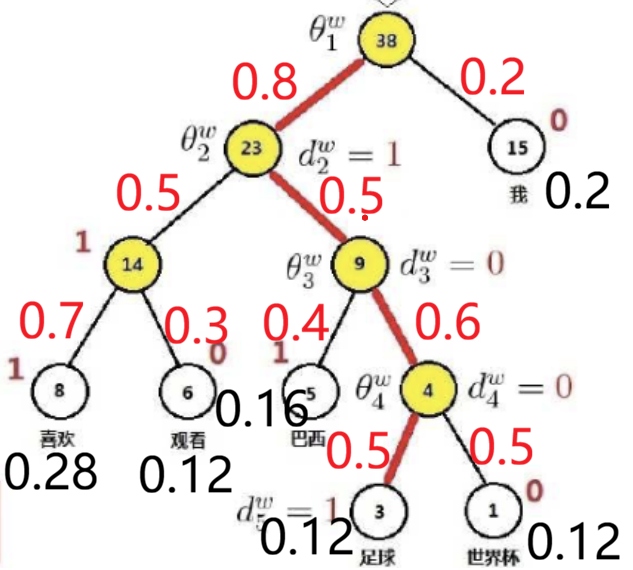
上面是一个具体的例子。对于一个上下文 w,所有可能的中心词的概率之和一定为 1,即所有叶子节点的输出结果之和一定为 1.
2.CBOW 模型会不会训练中心词的词向量呢?
从单词训练来说的话,并不会训练中心词的词向量,因为模型的输入是上下文的词向量,其中不包含中心词的词向量,所以不会更新中心词的词向量。
但是从多次训练来看的话,本轮的词向量肯定也会当作上下文词向量作为输入,从而进行训练。
3.Hierarchical softmax 有使用 softmax 吗?
虽然 Hierarchical Softmax 名字中带有 softmax,实际计算中只使用 sigmoid 进行一系列二分类(Bernoulli)预测; 这些 Bernoulli 概率在树结构中被组合,从而等价地定义了一个 Multinomial Logistic(softmax)形式的条件概率分布。
Skip-gram
skip-gram 是根据中心词预测上下文出现的概率,优化的目标也是使正确的上下文出现的概率最大化。
4.为什么模型训练出来的词向量会有语义结构呢?
使用 skip-gram 模型可以很容易的解释这个问题。假如有两个相似的词:“小狗”和“小猫”。那么这两个词的上下文肯定很相似,那么 skip-gram 模型的输出肯定也很相似。当训练好的模型的输出的结果很相似的时候,很大概率可以保证这两个词的词向量相似度很高,从而保证了训练出来的词向量有语义结构。
Negtative Sample 模型
NEG 的目的是用来提高训练速度和改善所得词向量质量的
现在考虑根据上下文预测中心词,如果需要预测所有字典中的词向量的概率,这个计算量是特别大的,所以这个时候使用 Sample,采样部分的负样本,然后加上正确的样本,然后使模型输出的正确的中心词概率最大,错误的中心词概率最小即可,这部分原文章论述的很详细,此处不再过多赘述。
5.对于同样的上下文,如何区分计算的不同的中心词的概率
negtative sample 模型是输出层没有 huffman 树,而是使用二分类器进行替代,输入为上下文变量为 X,中心词 u,输出为在这个上下文中出现中心词的概率。对不同的中心词就能获得不同的概率