Gaming Behavior Predict
Gaming Behavior Predict
小组作业
背景
游戏或许是一种策略游戏,但数据集显示,玩家行为背后的指标远非如此简单。在本篇笔记中,我们将深入分析一个捕捉在线游戏行为细微差别的数据集,挖掘隐藏的模式,并构建一个预测模型,以检验我们能否预测玩家的参与度。
商业问题
-
如何根据之前玩家的行为预测玩家在游戏中的参与度。通过预测玩家的活跃程度,游戏开发商可以提前识别出潜在的流失玩家,从而采取针对性的措施,如推送奖励、个性化推荐等,提高玩家的留存率和忠诚度。
-
玩家重要特征选取:并不是所有特征对玩家的参与度都有很重要的作用,玩家的参与度往往是由几个重要的特征决定的,找到重要的特征有利于商家针对性的优化产品。
数据
使用公开数据集 Predict Online Gaming Behavior Dataset该数据集涵盖了与在线游戏环境中玩家行为相关的全面指标和人口统计数据。它包括玩家人口统计信息、游戏特定细节、参与度指标以及反映玩家留存率的目标变量等变量。
实现的具体流程
-
首先对数据进行预处理,将类别信息转化为int类型,使用labelEncoder,并且查看是否有缺失值存在。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53# Import necessary libraries and suppress warnings
import warnings
warnings.filterwarnings('ignore')
import numpy as np
import pandas as pd
import time
import matplotlib
matplotlib.use('Agg') # use Agg backend for matplotlib
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
import math
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, StandardScaler
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, confusion_matrix, roc_curve, auc
# For reproducibility
np.random.seed(42)
file_path = 'online_gaming_behavior_dataset.csv'
df = pd.read_csv(file_path, encoding='ascii', delimiter=',')
# A little dry humor for the data geeks: If our visualizations don't win you over, at least our code comments might.
# Data Cleaning and Preprocessing
# Check for missing values and data types
print('Data types:')
print(df.dtypes)
print('\nMissing values per column:')
print(df.isnull().sum())
# In our dataset, we assume there are no date columns. However, if any date strings are found, you might use pd.to_datetime
# Encode categorical features
categorical_cols = ['Gender', 'Location', 'GameGenre', 'GameDifficulty', 'EngagementLevel']
# Label encoding for categorical columns for simplicity in both EDA and predictive modeling
le = LabelEncoder()
for col in categorical_cols:
# It's a common pitfall to not check for missing values before encoding
df[col] = df[col].astype(str) # ensure textual data
df[col] = le.fit_transform(df[col])
# Scaling numeric features for better performance in the prediction model
numeric_cols = ['Age', 'PlayTimeHours', 'InGamePurchases', 'SessionsPerWeek', 'AvgSessionDurationMinutes', 'PlayerLevel', 'AchievementsUnlocked']
scaler = StandardScaler()
df[numeric_cols] = scaler.fit_transform(df[numeric_cols])
# Final dataset preview
print('\nCleaned dataset preview:')
df.head()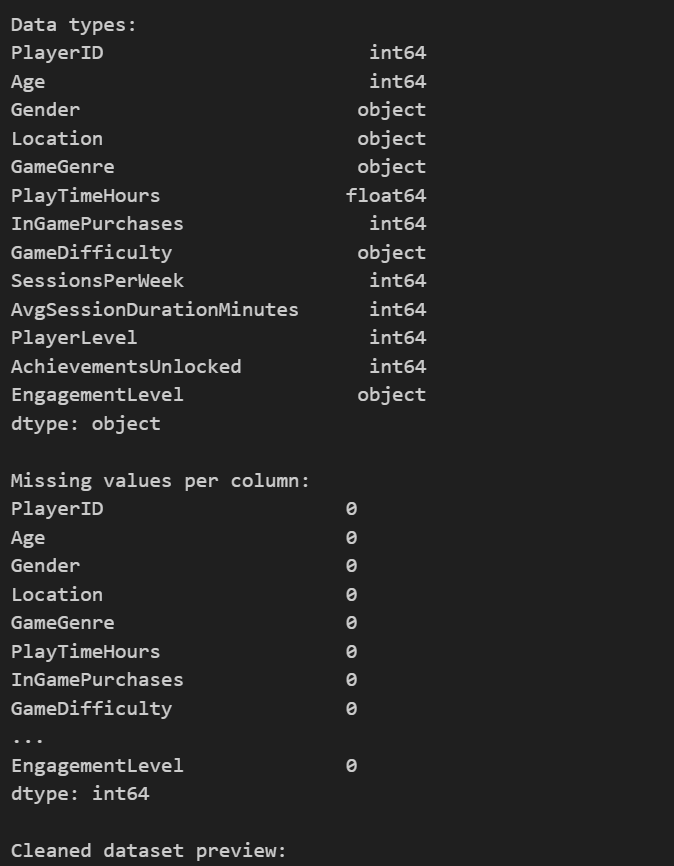
2.对数据进行可视化,简略查看数据的分布和之间的联系
1 | # Exploratory Data Analysis |
部分结果如下:
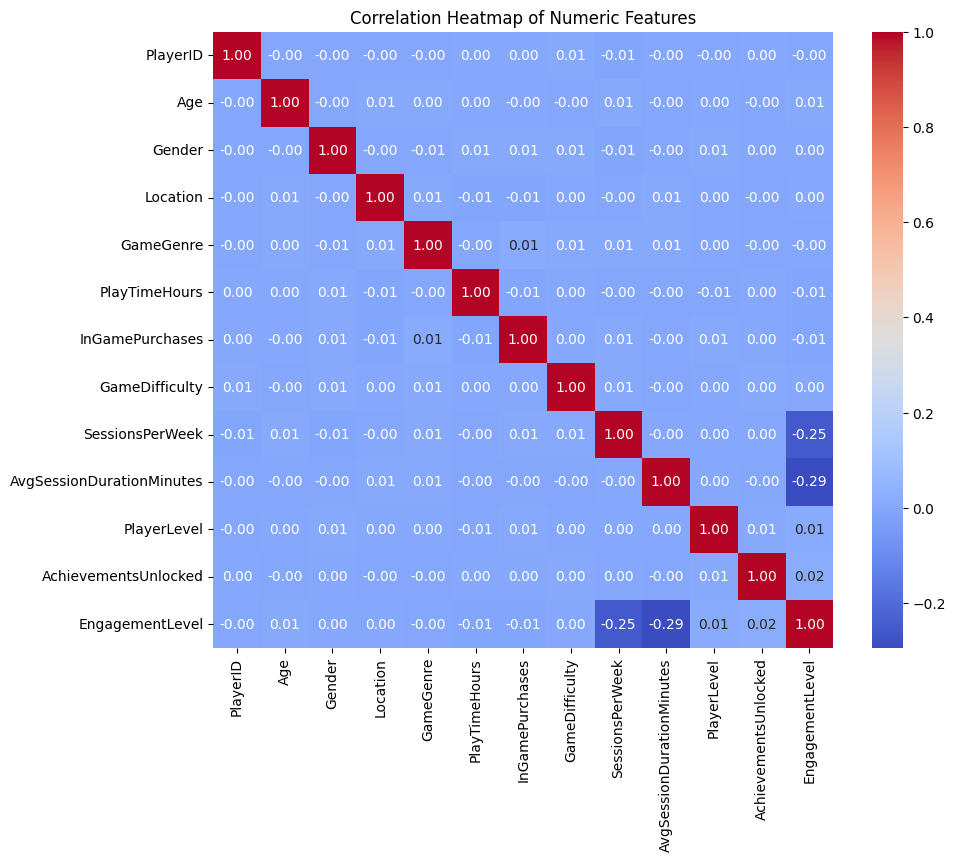
从上面的第三幅图热点图中可以看出:AvgSessionDurationMinutes和SessionsPerWeek与要预测的结果EngagementLevel都有很强的关联。
3.训练基准模型,使用全部的特征进行训练,此时选用随机森林作为模型。并且计算出混淆矩阵和ROC曲线以及特征重要性
1 | # Predictive Modeling |
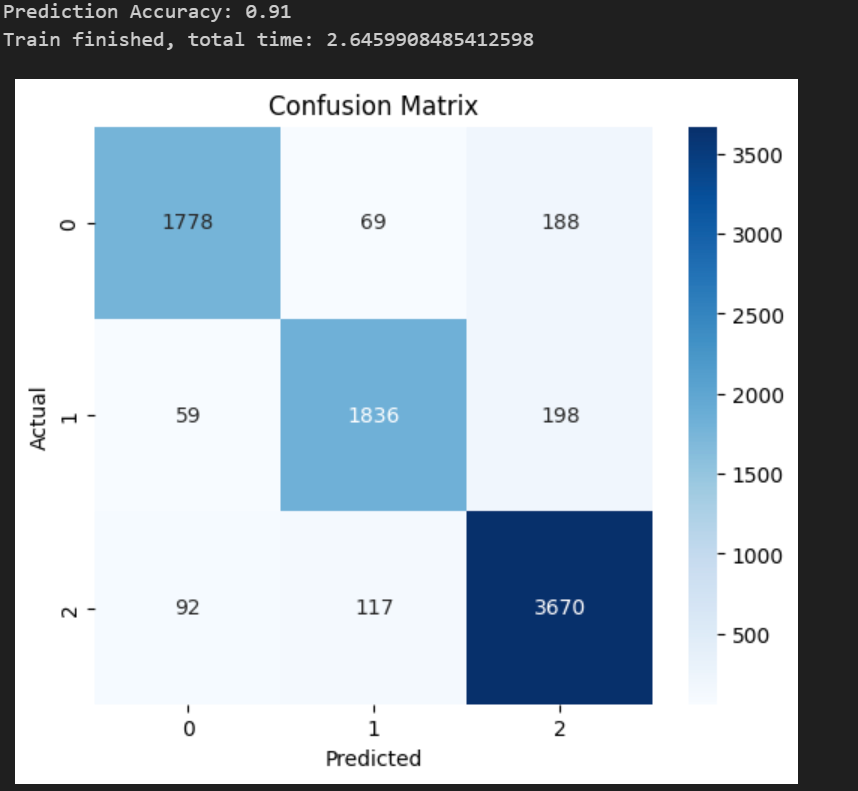
训练的准确度为0.91,验证了模型的可用性,并且训练的时间为2.64,作为基准将和后面的进行对比。
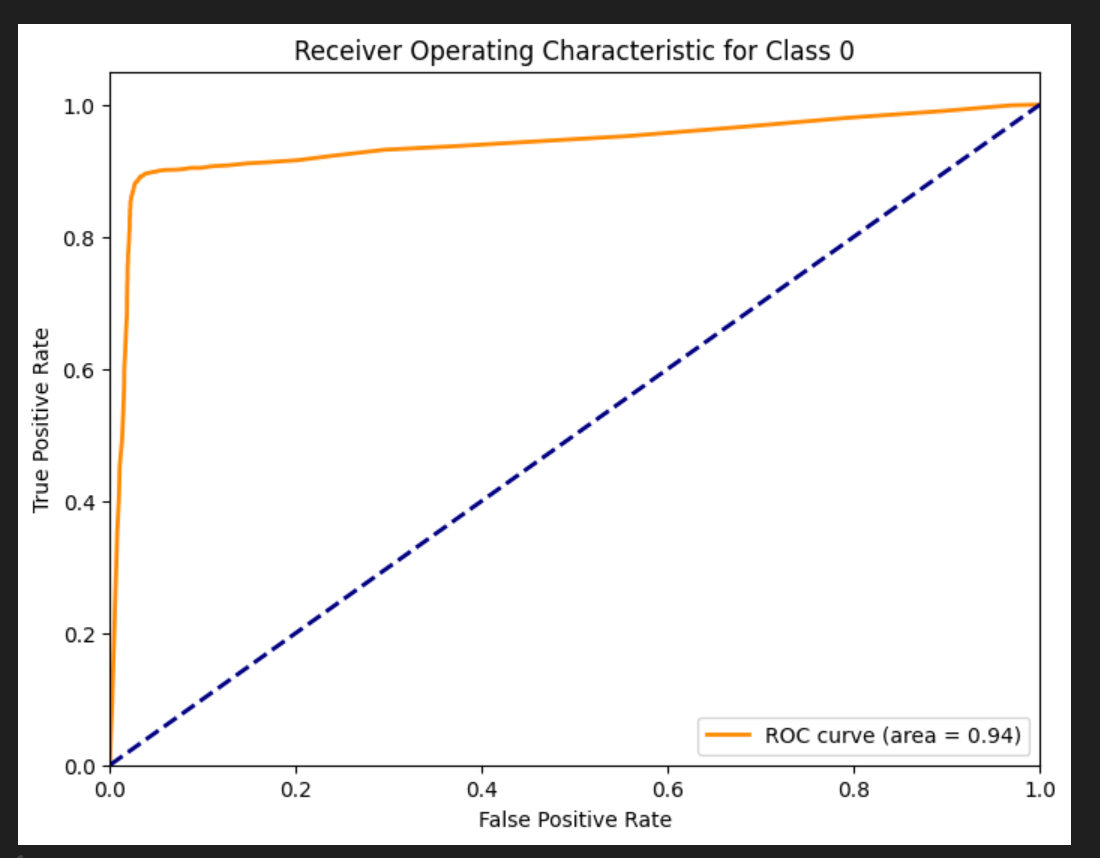
AUC值为0.94,再次验证该模型的可用性,具体ROC和AUC的计算参考另一篇文档 ROC曲线和AOC值
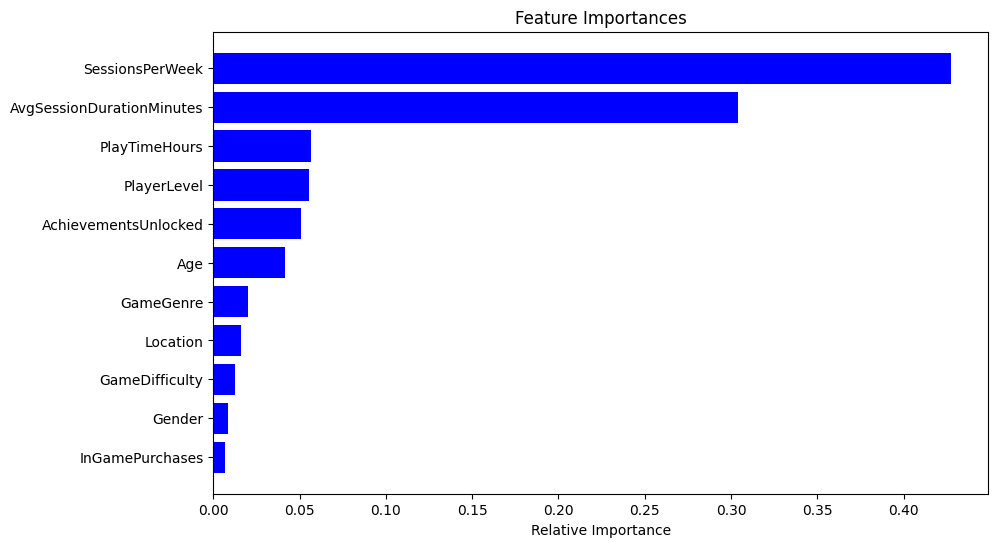
最后是特征的重要度,与上面数据分析部分一致,AvgSessionDurationMinutes和SessionsPerWeek与要预测的结果EngagementLevel都有很强的关联。
4.选取不同的特征组合进行训练模型:选取的逻辑根据上图特征重要程度的图片,按照重要程度从低到高依次累积删除,具体就是先删除0个特征,此时就是上面的基准模型,然后删除一个,就是最后一个特征:InGamePurchases。然后累计删除两个:Gender+InGamePurchases。依次类推。
1 | features_sorted=[features.columns[i] for i in indices] |
部分输出如下:

5.可视化输出
1 | X=list(range(0,len(features_sorted)-reserve_num+1)) |
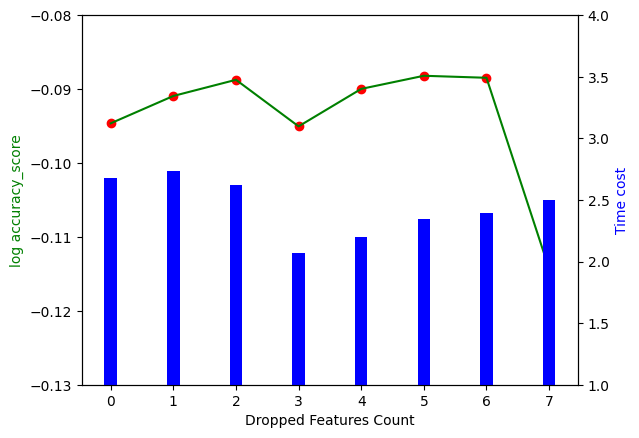
最终结果如上图所示,其中横坐标是删去的特征数量,左边的竖坐标是训练的准确度,为了更好的区分几个相近的准确度,使用 ,对应折线图。右侧的竖坐标是训练消耗的时间,对应柱状图。结果展示了两个结论:
- 并不是将所有特征都使用到模型效果才好,随着特征数量的减少,训练结果分数反而可能会变好,并且过多的输入特征会导致训练时间的增加,增加企业时间成本。
- 当删除7个特征的时候,准确度大幅减少,说明删除的第7个以及还没有删除的特征都有很强的作用,企业可以针对这几个特征进行优化