基于自编码器补全缺失特征值
基于自编码器补全缺失特征值
背景:不同的样本的特征值可能不完全一致,也有可能有部分样本的特征值会有所缺失,也有可能数据的来源不一致,比如对于同一个实验,不同的实验室得到的最终数据标注特征不一定一致,当想要混合使用这些数据的时候就必须天填充缺失值。
为了使用特征值数量不同的样本,首先就必须统一特征值的数量。那么有两种策略可以选择,一个是使用共同都有的特征,直接丢弃掉不同的特征,这种策略会导致特征值数量降低,并且有可能样本的特征值并没有交集。第二种策略是使用某种技术来填充特征值,使特征值少的样本经过填充之后与其他样本具有同样的特征。第二个策略有一个前提要求:缺失的特征值必须与其他的特征值有一定的关系。如果没有关系的话,相当于这个特征是独立于其他的,这个时候如果还使用其他的特征预测这个特征的话,无异于“猜”。
论文中模型实现的功能:
能够对不同的特征子集进行补全,并且缺失的特征值可以是多个。
模型原理:
模型训练:
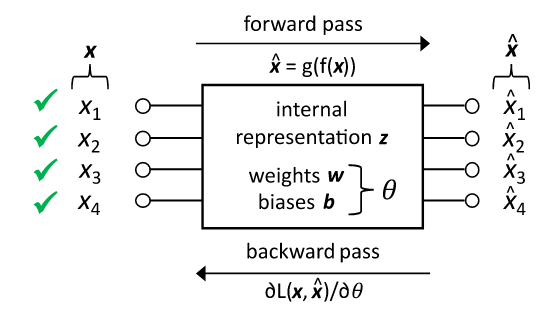
模型的训练就是使用自编码器进行训练,输入和输出是一致的都是特征值最全的一组样本。注意此训练的参数是自编码器中的参数。
一旦模型训练完成之后,固定自编码器中的参数。
预测缺失值:
这篇论文中预测缺失值的方式与其他的方式很不一样。其他很多时候,当一个模型训练好之后,将输入送入模型,模型得到的结果就是输出。但是此处则不一样。
模型如下所示:
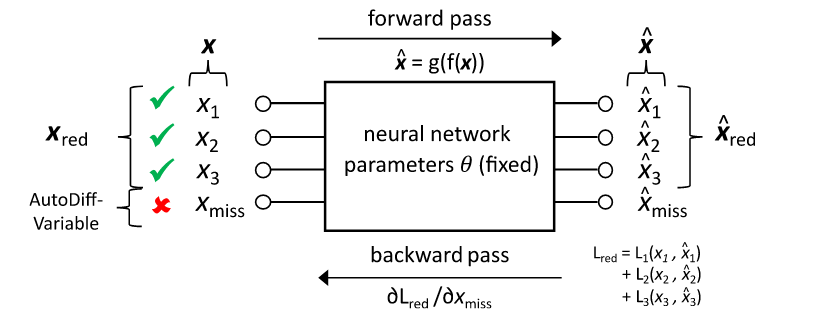
首先是没有已有的特征,是缺失的特征.将看作一个参数,一个可训练的参数,初始值为0。
然后将X送入训练好的自编码器,能够得到输出,然后就能得到一个损失函数,此时的损失函数只使用已知的特征进行计算:
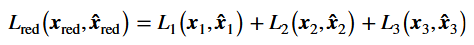
因为自编码器的参数已经固定,损失函数输出可以看作一个只与有关的函数。
此时有一个核心思想:最优的一定会使最低
那么现在问题就变成了找到最优的使最低,
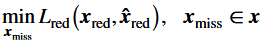
可以使用梯度下降来求得最优的
具体算法:

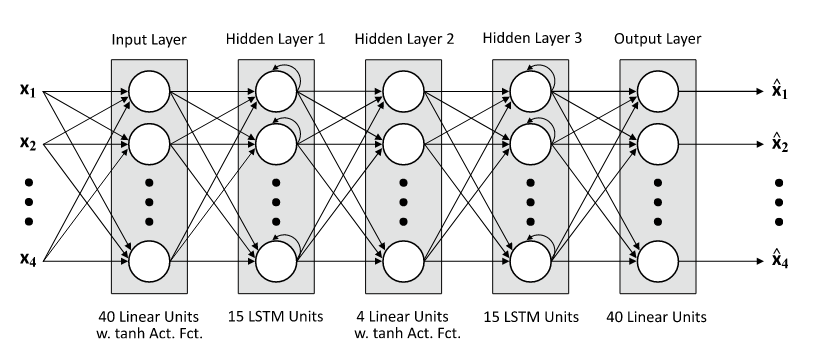
论文中使用的自编码器的具体模型:
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Kapi Blog!