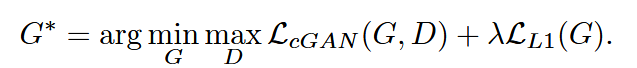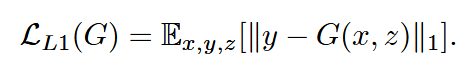classUnetGenerator(nn.Module): """Create a Unet-based generator"""
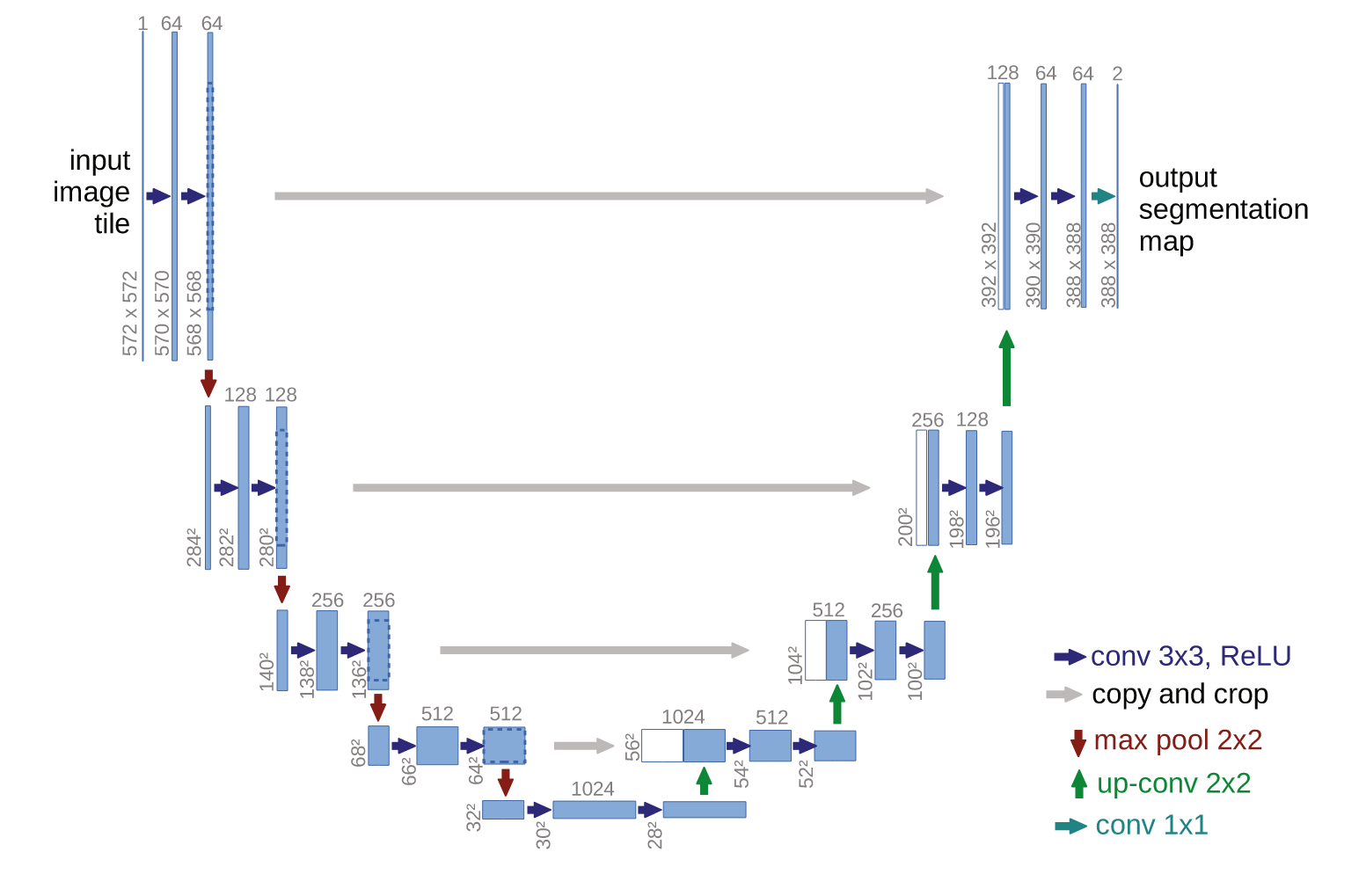
def__init__(self, input_nc, output_nc, num_downs, ngf=64, norm_layer=nn.BatchNorm2d, use_dropout=False): """Construct a Unet generator Parameters: input_nc (int) -- the number of channels in input images output_nc (int) -- the number of channels in output images num_downs (int) -- the number of downsamplings in UNet. For example, # if |num_downs| == 7, image of size 128x128 will become of size 1x1 # at the bottleneck ngf (int) -- the number of filters in the last conv layer norm_layer -- normalization layer We construct the U-Net from the innermost layer to the outermost layer. It is a recursive process. """ super(UnetGenerator, self).__init__() # construct unet structure unet_block = UnetSkipConnectionBlock(ngf * 8, ngf * 8, input_nc=None, submodule=None, norm_layer=norm_layer, innermost=True) # add the innermost layer for i inrange(num_downs - 5): # add intermediate layers with ngf * 8 filters unet_block = UnetSkipConnectionBlock(ngf * 8, ngf * 8, input_nc=None, submodule=unet_block, norm_layer=norm_layer, use_dropout=use_dropout) # gradually reduce the number of filters from ngf * 8 to ngf unet_block = UnetSkipConnectionBlock(ngf * 4, ngf * 8, input_nc=None, submodule=unet_block, norm_layer=norm_layer) unet_block = UnetSkipConnectionBlock(ngf * 2, ngf * 4, input_nc=None, submodule=unet_block, norm_layer=norm_layer) unet_block = UnetSkipConnectionBlock(ngf, ngf * 2, input_nc=None, submodule=unet_block, norm_layer=norm_layer) self.model = UnetSkipConnectionBlock(output_nc, ngf, input_nc=input_nc, submodule=unet_block, outermost=True, norm_layer=norm_layer) # add the outermost layer
classNLayerDiscriminator(nn.Module): """Defines a PatchGAN discriminator"""
def__init__(self, input_nc, ndf=64, n_layers=3, norm_layer=nn.BatchNorm2d): """Construct a PatchGAN discriminator Parameters: input_nc (int) -- the number of channels in input images ndf (int) -- the number of filters in the last conv layer n_layers (int) -- the number of conv layers in the discriminator norm_layer -- normalization layer """ super(NLayerDiscriminator, self).__init__() iftype(norm_layer) == functools.partial: # no need to use bias as BatchNorm2d has affine parameters use_bias = norm_layer.func == nn.InstanceNorm2d else: use_bias = norm_layer == nn.InstanceNorm2d
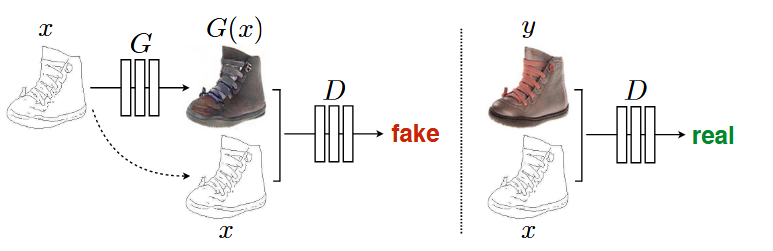
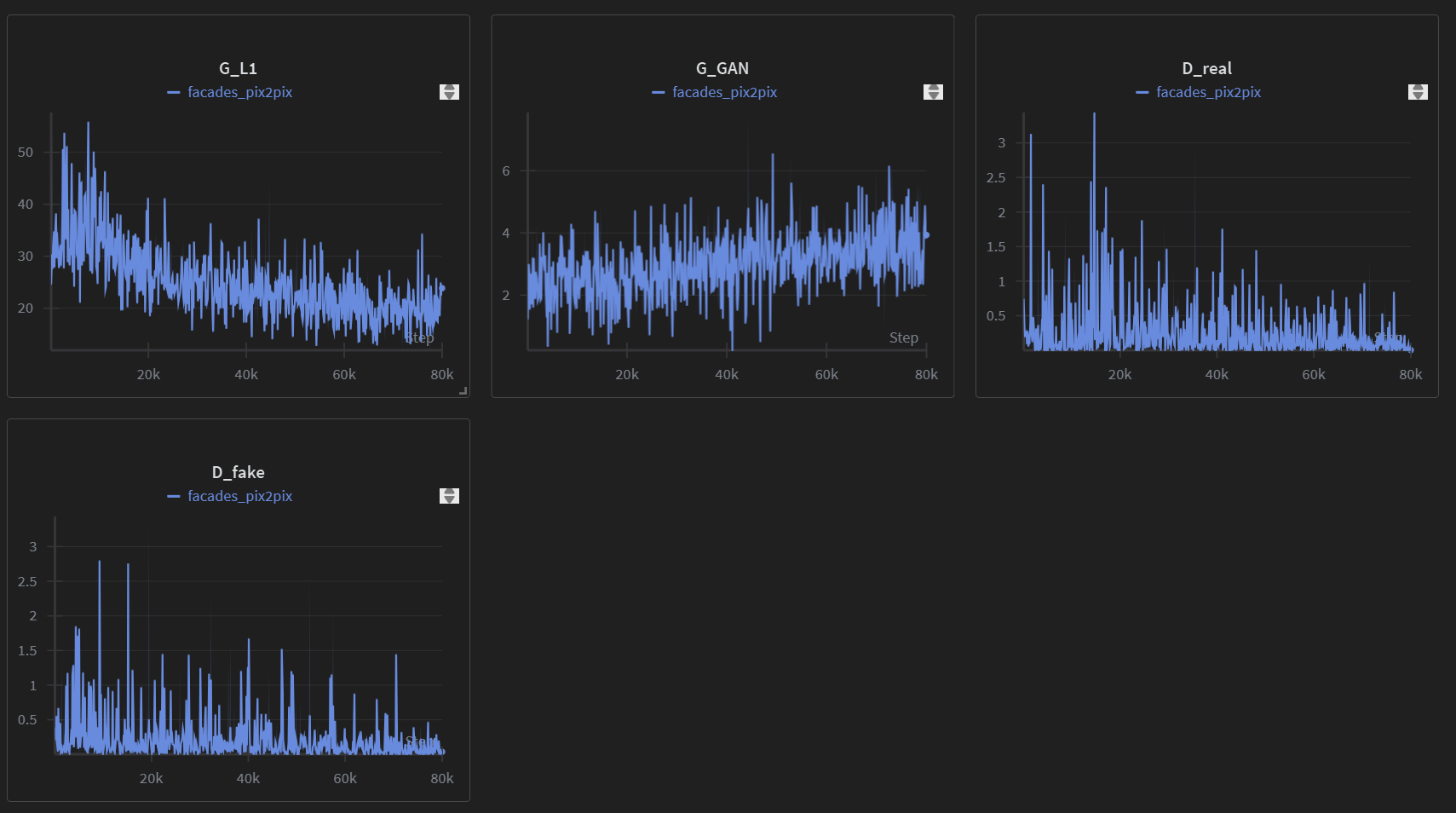
defbackward_D(self): """Calculate GAN loss for the discriminator""" # Fake; stop backprop to the generator by detaching fake_B fake_AB = torch.cat((self.real_A, self.fake_B), 1) # we use conditional GANs; we need to feed both input and output to the discriminator pred_fake = self.netD(fake_AB.detach()) self.loss_D_fake = self.criterionGAN(pred_fake, False) # Real real_AB = torch.cat((self.real_A, self.real_B), 1) pred_real = self.netD(real_AB) self.loss_D_real = self.criterionGAN(pred_real, True) # combine loss and calculate gradients self.loss_D = (self.loss_D_fake + self.loss_D_real) * 0.5 self.loss_D.backward()
defbackward_G(self): """Calculate GAN and L1 loss for the generator""" # First, G(A) should fake the discriminator fake_AB = torch.cat((self.real_A, self.fake_B), 1) pred_fake = self.netD(fake_AB) self.loss_G_GAN = self.criterionGAN(pred_fake, True) # Second, G(A) = B self.loss_G_L1 = self.criterionL1(self.fake_B, self.real_B) * self.opt.lambda_L1 # combine loss and calculate gradients self.loss_G = self.loss_G_GAN + self.loss_G_L1 self.loss_G.backward()